
Integrating robots.txt, meta robots tags, and canonical URLs requires understanding their distinct roles and how they interact to guide search engines in crawling and indexing your site effectively.
-
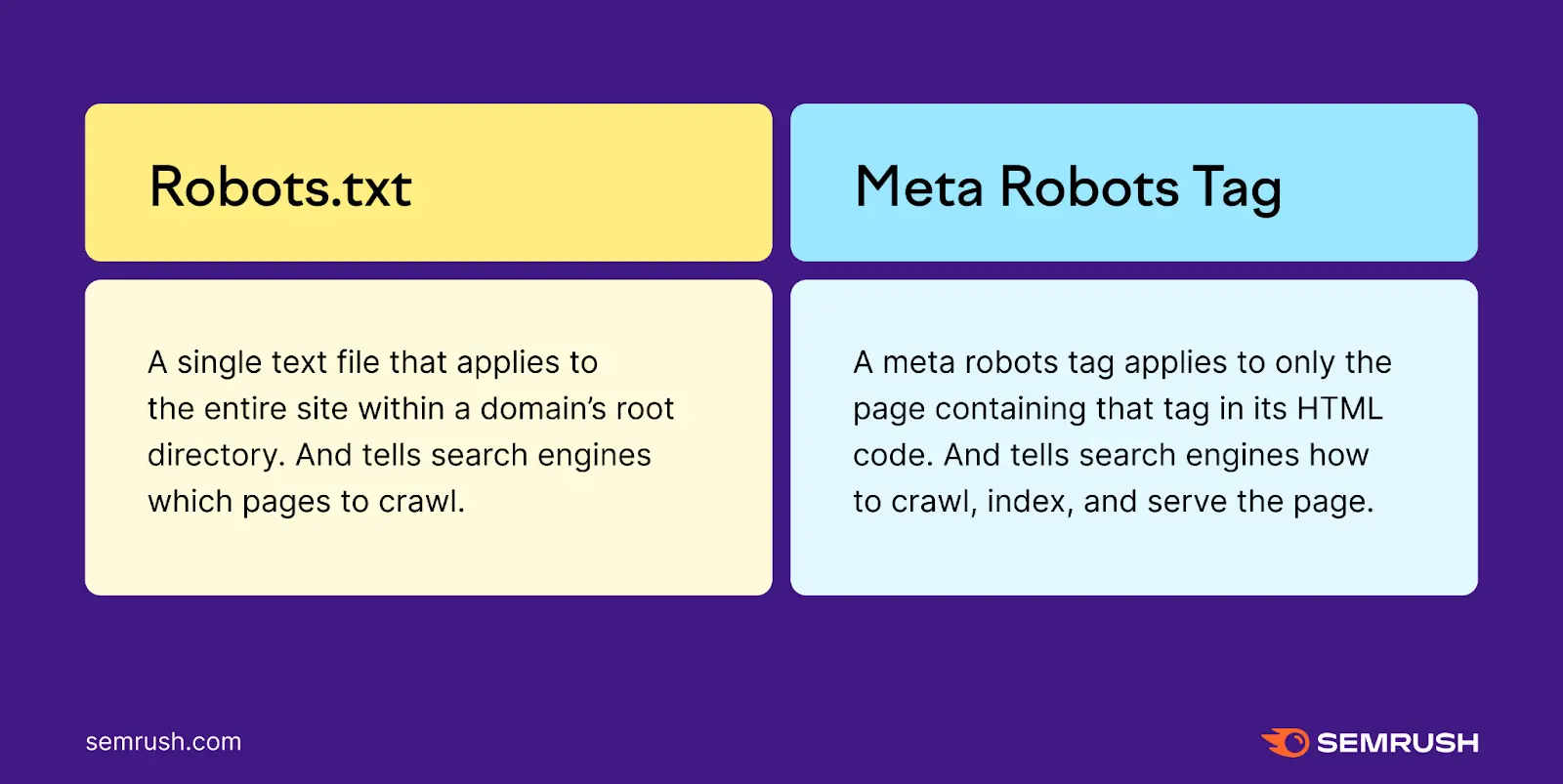
robots.txt is a file placed at the root of your domain that blocks search engine bots from crawling specific URLs or directories. However, if a URL is blocked by robots.txt, search engines cannot see meta robots tags on that page because they do not crawl it. This means robots.txt prevents crawling but does not directly control indexing.
-
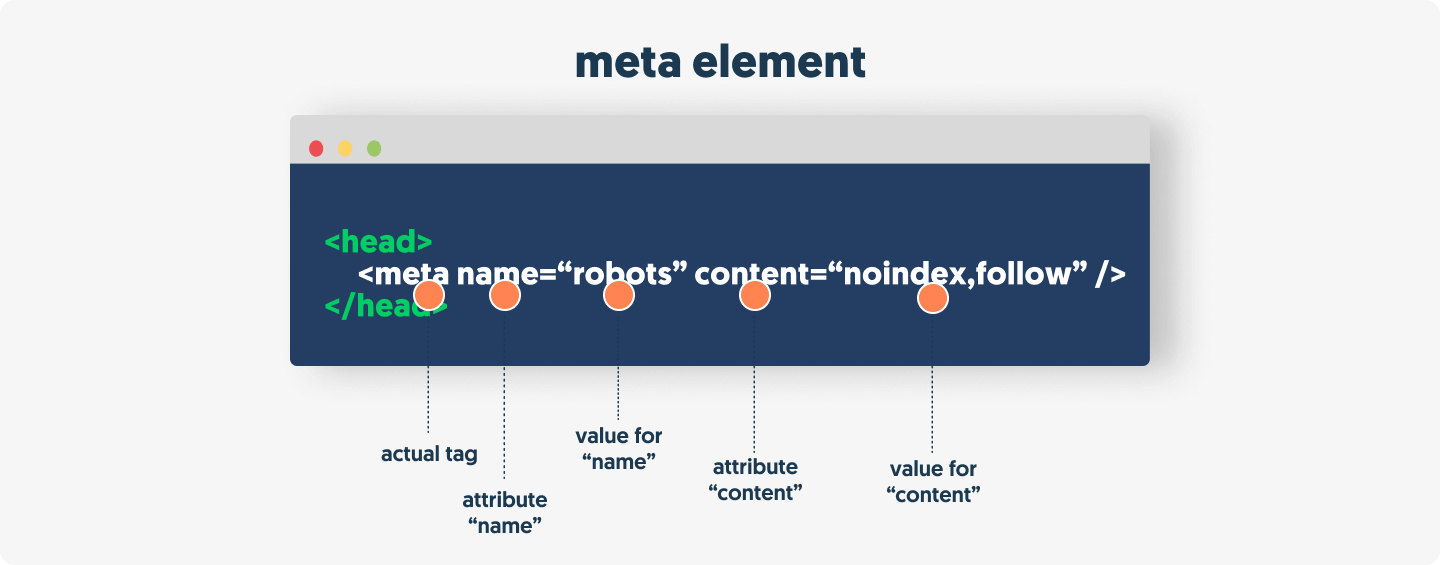
Meta robots tags are HTML tags placed in the
<head>of a page that instruct search engines whether to index the page and/or follow its links (e.g.,noindex, nofollow). These tags only work if the page is crawlable. If a page is blocked by robots.txt, meta robots directives are ignored because the bot cannot access the page to read the tag. -
Canonical URLs are HTML link tags (
<link rel="canonical" href="URL">) that suggest to search engines which version of a page is the preferred or original one among duplicates. Canonical tags help consolidate ranking signals and avoid duplicate content issues but are treated as hints, not strict directives.
Key integration points:
-
Avoid blocking pages with robots.txt if you want meta robots tags or canonical tags on those pages to be effective. If a page is blocked by robots.txt, search engines won’t crawl it and thus won’t see meta robots tags or canonical URLs there.
-
You can use meta robots tags and canonical tags together on crawlable pages. Google now accepts this combination, even though they sometimes send conflicting signals. For example, a page can have a canonical tag pointing to a preferred URL and a meta robots tag with
noindexto prevent indexing while still signalling canonical preference. -
Use robots.txt primarily to block crawling of low-value or sensitive content you do not want bots to access at all. Use meta robots tags to control indexing and link following on pages that are crawlable. Use canonical tags to manage duplicate content and consolidate SEO signals across similar pages.
-
Be cautious with directives like
noindex, followin meta robots tags: Google may eventually treat this asnoindex, nofollow.
Summary:
| Element | Purpose | Works if Page is Blocked by robots.txt? | Interaction Notes |
|---|---|---|---|
| robots.txt | Blocks crawling | No (bots don’t crawl blocked pages) | Prevents bots from seeing meta robots or canonical tags on blocked pages |
| meta robots tag | Controls indexing & link following | No (requires crawl to be seen) | Effective only on crawlable pages |
| canonical URL | Suggests preferred URL for duplicates | No (requires crawl to be seen) | Helps consolidate duplicate content signals; treated as a hint |
To integrate effectively, ensure pages you want indexed or canonicalized are crawlable (not blocked by robots.txt), use meta robots tags to control indexing where needed, and use canonical tags to indicate preferred URLs for duplicate or similar content.














WebSeoSG offers the highest quality website traffic services in Singapore. We provide a variety of traffic services for our clients, including website traffic, desktop traffic, mobile traffic, Google traffic, search traffic, eCommerce traffic, YouTube traffic, and TikTok traffic. Our website boasts a 100% customer satisfaction rate, so you can confidently purchase large amounts of SEO traffic online. For just 40 SGD per month, you can immediately increase website traffic, improve SEO performance, and boost sales!
Having trouble choosing a traffic package? Contact us, and our staff will assist you.
Free consultation